MySQL Index 정리 및 팁
MySQL의 인덱스란 무엇인가?
인덱스는 MySQL에서 데이터베이스 테이블의 데이터 검색 속도를 향상시키는 자료구조입니다. 책의 색인과 유사하게, 데이터베이스 인덱스는 전체 테이블을 스캔하지 않고도 데이터베이스 엔진이 특정 행을 빠르게 찾을 수 있게 해줍니다.
MySQL은 주로 정렬된 구조로 데이터를 저장하여 효율적인 검색, 삽입, 삭제 작업을 가능하게 하는 B-Tree 인덱스를 사용합니다.
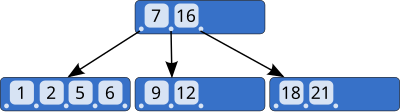
B-Tree 인덱스 구조
B-Tree(Balanced Tree) 인덱스는 다음과 같은 주요 특징을 가집니다:
- 루트 노드: 브랜치 노드를 가리키는 트리의 최상위 레벨
- 브랜치 노드: 키와 자식 노드에 대한 포인터를 포함하는 중간 레벨
- 리프 노드: 인덱스된 값과 행 포인터를 포함하는 최하위 레벨
- 균형 구조: 모든 리프 노드는 루트로부터 동일한 거리에 위치
- 정렬된 데이터: 트리 내의 데이터는 정렬된 순서로 유지됨
- 로그 시간 복잡도: O(log n) 시간 내에 데이터를 찾을 수 있음
카디널리티 이해하기
카디널리티는 컬럼의 데이터 값 고유성을 나타냅니다. 인덱스 효율성을 결정하는 중요한 요소입니다.
- 높은 카디널리티: 고유한 값이 많은 컬럼 (예: 기본 키, 주민등록번호, 이메일 주소)
- 중간 카디널리티: 적당한 수의 고유한 값을 가진 컬럼 (예: 우편번호, 날짜)
- 낮은 카디널리티: 고유한 값이 적은 컬럼 (예: 성별, 상태 플래그, 국가 코드)
카디널리티가 높을수록 인덱스 효율성이 높아집니다. MySQL의 옵티마이저는 쿼리 실행을 위해 어떤 인덱스를 사용할지 결정할 때 카디널리티 통계를 사용합니다.
카디널리티 확인 방법:
SHOW INDEX FROM 테이블명;MySQL의 인덱스 유형
B-Tree가 기본 유형이지만, MySQL은 여러 인덱스 유형을 지원합니다:
- B-Tree 인덱스: 대부분의 시나리오에 적합한 범용 인덱스 유형
- 해시 인덱스: MEMORY 테이블에서만 사용 가능하며, 동등 비교에 최적화됨
- R-Tree 인덱스: 공간 데이터 유형(GEOMETRY)에 사용됨
- 전문 인덱스(Full-Text Index): TEXT, CHAR 또는 VARCHAR 컬럼에서 텍스트 기반 검색에 사용
- 역 인덱스(Inverted Index): 전문 검색을 위해 내부적으로 사용됨
인덱스 동작 방식
1. 단일 컬럼 인덱스
단일 컬럼에 인덱스를 생성할 때:
CREATE INDEX idx_name ON customers(last_name);- 카디널리티가 높은 컬럼에 가장 적합
- WHERE 절, JOIN 조건 또는 ORDER BY 문에서 자주 사용되는 컬럼에 이상적
- 사용 사례: 고객 ID, 이메일 주소 또는 타임스탬프
실제 예시:
-- 단일 컬럼 인덱스 생성
CREATE INDEX idx_email ON users(email);
-- 이 인덱스를 사용하는 쿼리
SELECT * FROM users WHERE email = 'user@example.com';2. 다중 개별 인덱스
서로 다른 컬럼에 별도의 인덱스를 생성할 때:
CREATE INDEX idx_fname ON customers(first_name);
CREATE INDEX idx_lname ON customers(last_name);MySQL은 여러 인덱스의 결과를 결합하기 위해 인덱스 병합(Index Merge) 최적화를 사용할 수 있습니다:
- 유니온 병합(Union Merge): OR 조건 사용 시 결과 결합
- 인터섹션 병합(Intersection Merge): AND 조건 사용 시 결과 결합
- 정렬-유니온 병합(Sort-Union Merge): 복잡한 OR 조건에 대한 특수 케이스
그러나 다중 개별 인덱스가 항상 다중 컬럼 인덱스보다 효율적인 것은 아닙니다.
3. 다중 컬럼(복합) 인덱스
여러 컬럼을 함께 인덱싱할 때:
CREATE INDEX idx_name ON customers(last_name, first_name, city);
주요 고려사항:
- 컬럼 순서가 매우 중요함
- 최적의 성능을 위해 높은 카디널리티에서 낮은 카디널리티 순으로 컬럼 배열
- "가장 왼쪽 접두사" 규칙 적용 - 쿼리는 왼쪽에서 오른쪽으로 컬럼을 사용해야 함
카디널리티 순서별 성능 비교
| 높은 → 낮은 카디널리티 순서 | 낮은 → 높은 카디널리티 순서 |
|---|---|
| CREATE INDEX idx_name ON users(id, status, created_at); | CREATE INDEX idx_name ON users(status, created_at, id); |
| 더 좋은 성능 | 더 나쁜 성능 |
MySQL은 다음 열을 참조하는 쿼리에 이 인덱스를 사용할 수 있습니다:
- last_name
- last_name, first_name
- last_name, first_name, city
하지만 다음만 사용하는 쿼리에는 사용할 수 없습니다:
- first_name
- city
- first_name, city
3.1 효율적인 다중 컬럼 인덱스 사용 조건
B-Tree 인덱스는 다음 연산자와 함께 효율적으로 작동합니다:
=(등호)>,<,>=,<=(비교)BETWEEN(범위)IN(값 목록)LIKE 'abc%'(가장 왼쪽에 고정된 패턴)
중요 참고사항:
- B-Tree 인덱스는 다음을 효율적으로 처리할 수 없습니다:
- 부정 연산자(
!=,NOT IN) - 인덱스된 컬럼에 적용된 함수(
YEAR(date_column)) LIKE '%abc'시작 부분에 와일드카드가 있는 패턴
- 부정 연산자(
- 조인 작업의 경우, 일치하는 데이터 유형과 크기를 가진 컬럼이 더 나은 성능을 보입니다
VARCHAR(10)과CHAR(10)은 호환되는 것으로 간주됨VARCHAR(10)과CHAR(15)는 호환되지 않음
인덱스 컬럼 크기와 성능
인덱스된 컬럼의 크기는 성능에 영향을 미칩니다. 더 작은 인덱스는:
- 더 적은 디스크 공간 필요
- 더 많은 항목이 메모리에 맞음
- 더 적은 디스크 I/O 작업 발생
크기와 성능별 데이터 유형 비교
| 데이터 유형 | 크기 | 성능 영향 |
|---|---|---|
| TINYINT | 1 바이트 | 매우 우수 |
| INT | 4 바이트 | 매우 좋음 |
| BIGINT | 8 바이트 | 좋음 |
| UUID (CHAR(36)) | 36 바이트 | 보통 |
| VARCHAR(100) | 가변 (최대 100 바이트) | 실제 데이터 길이에 따라 다름 |
풀 테이블 스캔을 피하는 팁
풀 테이블 스캔은 MySQL이 인덱스를 사용하는 대신 전체 테이블을 읽을 때 발생하며, 특히 큰 테이블의 경우 성능에 심각한 영향을 미칠 수 있습니다.
- 쿼리 패턴에 기반한 적절한 인덱스 생성
EXPLAIN을 사용한 쿼리 분석:EXPLAIN SELECT * FROM orders WHERE status = 'shipped';- 정기적인 통계 업데이트:
ANALYZE TABLE orders; - WHERE 절에서 인덱스된 컬럼에 함수 사용 피하기:
-- 나쁨 (인덱스 사용 안함) SELECT * FROM orders WHERE YEAR(created_at) = 2023; -- 좋음 (인덱스 사용함) SELECT * FROM orders WHERE created_at BETWEEN '2023-01-01' AND '2023-12-31'; - 복잡한 표현식을 피하고 WHERE 절을 단순하게 유지
인덱스 유지 관리
인덱스는 효율성을 유지하기 위해 관리가 필요합니다:
- 인덱스 사용량 모니터링:
SELECT * FROM performance_schema.table_io_waits_summary_by_index_usage WHERE object_schema = '데이터베이스명'; - 사용되지 않는 인덱스 찾기:
SELECT * FROM sys.schema_unused_indexes; - 단편화된 인덱스 재구축:
ALTER TABLE 테이블명 DROP INDEX 인덱스명; ALTER TABLE 테이블명 ADD INDEX 인덱스명 (컬럼_목록); - 주기적인 재구성 고려:
OPTIMIZE TABLE 테이블명;
인덱스를 사용하지 말아야 할 경우
인덱스가 항상 유익한 것은 아닙니다:
- 풀 스캔이 인덱스 조회보다 빠른 작은 테이블
- 카디널리티가 낮은 컬럼 (고유 값이 적음)
- 읽기보다 쓰기 작업이 빈번한 테이블
- WHERE 절에서 거의 사용되지 않는 컬럼
- 이미 많은 인덱스를 가진 테이블 (각 인덱스는 INSERT/UPDATE/DELETE 작업에 오버헤드 추가)
MySQL 인덱싱 모범 사례
- WHERE, JOIN 및 ORDER BY에 사용되는 컬럼에 인덱스 생성
- 자주 결합되는 컬럼에 복합 인덱스 생성
- 다중 컬럼 인덱스에서 컬럼 순서 고려
- 과도한 인덱싱 피하기 - 각 인덱스는 쓰기 작업 오버헤드 증가
- 인덱스 정기적인 모니터링 및 유지관리
- 가능한 경우 커버링 인덱스 사용 (쿼리에 필요한 모든 컬럼 포함)
- 대형 텍스트 컬럼에 부분 인덱스 고려:
CREATE INDEX idx_product_name ON products(name(20));- 인덱스 사용 확인을 위한 EXPLAIN 사용
- 인덱스 크기를 최소화하기 위한 적절한 컬럼 데이터 유형 선택
- 사용되지 않는 인덱스 삭제로 쓰기 성능 향상
참고 자료:
'Database > My SQL' 카테고리의 다른 글
| [DB] MySQL 파티션 테이블 가이드 (0) | 2025.01.04 |
|---|---|
| [DB] 파티션 테이블(Partition Table)이란? (0) | 2025.01.04 |
| 커버링 인덱스 (Covering Index) 를 사용해서 쿼리 최적화하기 (0) | 2024.11.30 |